Use Cases
Docs
Blog Articles
BlogResources
Pricing
PricingAggregate streaming data in real-time with WebAssembly

Engineer, InfinyOn

Fluvio is a high-performance, distributed, programmable streaming platform for real-time data. We’re making steady progress adding new inline data processing capabilities, building on our SmartModules feature that allows users to write custom code to interact with their streaming data. SmartModules are written in Rust, compiled to WebAssembly, and executed on Fluvio’s Streaming Processing Units to manipulate data inline.
This week we’re happy to announce Aggregations for SmartModules! Aggregates let you define functions that combine each record in a stream with some long-running state, or “accumulator”. Depending on the data that you’re working with, an accumulator can be something as simple as a summed number, or some structured data like a table of aggregated data points. In this blog, I’m going to introduce three examples of aggregates: summing a stream of integers, calculating an incremental average, and finally, tracking multiple sums with a key-value accumulator.
You can find the full code for the examples covered in the blog in the fluvio-smartmodule-examples repository.
Aggregation concepts
To kick things off, I want to give some visual insight into what’s happening when we talk about Aggregations. Like I mentioned above, an Aggregate is essentially a function that takes an “accumulated” value and combines it with a new input value.
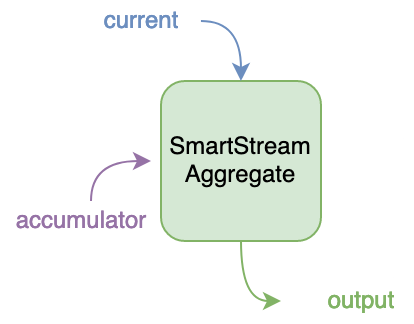
When we write our SmartModules Aggregate function in Rust, the inputs and outputs directly correlate with this conceptual model of an aggregation:

When we apply an aggregation function to a stream of input values, we get a stream of output values that represent the values of the accumulator over time. In this visual, the green nodes represent each invocation of our aggregation function, the blue nodes are values from our input stream, and the purple nodes are values in our output stream. We also have an “initial” accumulator value (shown in the white dotted box), which is not included in the output stream but which is used as the first accumulator input to the aggregate function.

Alright, with that background out of the way, let’s take a look at some code examples!
Follow along: Use the SmartModule template
If you’d like to follow along with the code samples, feel free to use the
cargo-generate template to get a project up and running quickly. If you don’t
have cargo-generate installed, you can install it with:
$ cargo install cargo-generate
Then, use this command to apply the template and create a new project folder. Be sure to use the “aggregate” type.
$ cargo generate --git https://github.com/infinyon/fluvio-smartmodule-template
⚠️ Unable to load config file: ~/.cargo/cargo-generate.toml
🤷 Project Name : aggregate-blog-sum
🔧 Generating template ...
✔ 🤷 Which type of SmartModule would you like? · aggregate
[1/7] Done: .cargo/config.toml
[2/7] Done: .cargo
[3/7] Done: .gitignore
[4/7] Done: Cargo.toml
[5/7] Done: README.md
[6/7] Done: src/lib.rs
[7/7] Done: src
🔧 Moving generated files into: `aggregate-blog-sum`...
✨ Done! New project created aggregate-blog-sum
This leads us right into our first example, since the aggregate template code shows off how to sum integers!
Example #1: Sum integers in a stream
Our first example is one of the simplest possible SmartModule Aggregate functions, which just takes an accumulated integer value and adds each new record to it.
The code generator created a sample file for us. Let’s navigate into our project directory and take a look at the sample code we were given:
$ cd aggregate-blog-sum && cat src/lib.rs
We should see the following SmartModule code:
use fluvio_smartmodule::{smartmodule, Result, Record, RecordData};
#[smartmodule(aggregate)]
pub fn aggregate(accumulator: RecordData, current: &Record) -> Result<RecordData> {
// Parse the accumulator and current record as strings
let accumulator_string = std::str::from_utf8(accumulator.as_ref())?;
let current_string = std::str::from_utf8(current.value.as_ref())?;
// Parse the strings into integers
let accumulator_int = accumulator_string.trim().parse::<i32>().unwrap_or(0);
let current_int = current_string.trim().parse::<i32>()?;
// Take the sum of the two integers and return it as a string
let sum = accumulator_int + current_int;
Ok(sum.to_string().into())
}
The first thing to know is that both the accumulator and the current record
are represented as binary data. This is powerful because it allows us to work
with truly arbitrary data, but it does require us to parse that data into a structured
form that’s easier to work with. In this example, we’re representing our records
as i32 (32-bit signed) integers, encoded in a UTF-8 string (this makes it easy
to interact with the numbers from the CLI).
Let’s look at how this SmartModule behaves when we apply it to a Fluvio stream.
First, let’s create a topic where we’ll produce and consume our data from.
$ fluvio topic create aggregate-ints
topic "aggregate-ints" created
Then we’ll produce some data to the topic. Remember, our goal here is to sum up integers in a stream, so we’ll produce some input integers to see what happens.
$ fluvio produce aggregate-ints
> 1
Ok!
> 1
Ok!
> 1
Ok!
> 1
Ok!
> 1
Ok!
> 10
Ok!
Finally, to view the output of processing this stream with our aggregate function, we need to compile our SmartModule and then point to it when we open our Consumer. If you’re following along with the template, run the following commands to build the SmartModule:
If you’ve never compiled for WASM before, you’ll need to install the proper rustup target.
You should only need to do this once.
$ rustup target add wasm32-unknown-unknown
Finally, we can actually compile the SmartModule.
$ cargo build --release
After running cargo build --release, we should be able to find the WASM binary
at target/wasm32-unknown-unknown/release/aggregate_blog_sum.wasm.
$ ls -la target/wasm32-unknown-unknown/release
.rwxr-xr-x 303Ki nick 23 Aug 16:50 -- aggregate_blog_sum.wasm
At this point, we can now use the Fluvio CLI to consume the records from our stream and process them with our freshly-minted SmartModule. Let’s try it out with the following command:
$ fluvio consume aggregate-ints -B --aggregate=target/wasm32-unknown-unknown/release/aggregate_blog_sum.wasm
Consuming records from the beginning of topic 'aggregate-ints'
1
2
3
4
5
15
As we can see, our stream of 1’s followed by a 10 were summed up and turned into a stream of the aggregation of records so far.
Example #2: Aggregate with initial value
This is a good opportunity to talk about the “initial value” of an aggregator. In our output
stream above, we can infer that the initial value must have been the integer zero (0), since
our first output value was identical to the first input value. However, the actual representation
of the “empty accumulator” is not actually a numeric zero, but rather a literal empty buffer of
bytes, the equivalent of an empty Rust Vec<u8>. The reason we get a numeric zero as our initial
accumulator in this example is because of this line in the code:
let accumulator_int = accumulator_string.trim().parse::<i32>().unwrap_or(0);
Here, we are taking our accumulator value as a string (an empty string, to be exact) and attempting
to parse it as a 32-bit integer. In Rust, we’ll fail to parse an integer from an empty string, so
we will fall back to the .unwrap_or(0) clause, which says to use the value we parsed if we were
successful, or to use 0 if we were not successful. This is a pattern I’ve found to be quite helpful
when parsing the accumulator into a structured value: if the accumulator can be parsed, parse it,
otherwise, supply a sane default value to be used instead.
If we want to specify an initial value other than “empty record”, we can use the --initial flag
in the Fluvio CLI to specify a file to use as the initial file. So let’s say we put the value 100
into a text file:
$ echo '100' > initial.txt
Then, we can re-run our consumer and give initial.txt as the initial value to use for our accumulator
value in the stream. To relate this back to the diagrams above, this becomes the new value in the dotted
white box.
$ fluvio consume aggregate-ints -B --initial=./initial.txt --aggregate=target/wasm32-unknown-unknown/release/aggregate_blog_sum.wasm
101
102
103
104
105
115
Next, we’ll look at a slightly more detailed example that uses a more complex accumulator type!
Example #3: Calculate an incremental average
Summing integers in a stream is nice, but it’s rather simplistic. Let’s try to create an Aggregator that calculates the average of every number we’ve seen so far in a stream. For this example, our input will still be a stream of numbers (floats this time), but we’ll need to keep additional information in our accumulator in order to perform our calculations.
In order to calculate an average incrementally, we need to know the following information at each step in our aggregation:
- the average of all the input we have seen so far,
- the number of inputs we have averaged, and
- the next input to add to our incremental average
We’ll store 1) and 2) in our accumulator, and read 3) from our stream of input records.
Follow along: create a new project
Let’s create a new SmartModule Aggregate project aggregate-blog-average to play with this new use-case:
$ cargo generate --git https://github.com/infinyon/fluvio-smartmodule-template
⚠️ Unable to load config file: ~/.cargo/cargo-generate.toml
🤷 Project Name : aggregate-blog-average
🔧 Generating template ...
✔ 🤷 Which type of SmartModule would you like? · aggregate
[1/7] Done: .cargo/config.toml
[2/7] Done: .cargo
[3/7] Done: .gitignore
[4/7] Done: Cargo.toml
[5/7] Done: README.md
[6/7] Done: src/lib.rs
[7/7] Done: src
🔧 Moving generated files into: `aggregate-blog-average`...
✨ Done! New project created aggregate-blog-average
Let’s jump right into the code for this example.
$ cd aggregate-blog-average
Paste the following code into your src/lib.rs file:
use serde::{Serialize, Deserialize};
use fluvio_smartmodule::{smartmodule, Result, Record, RecordData};
#[derive(Default, Serialize, Deserialize)]
struct IncrementalAverage {
average: f64,
count: u32,
}
impl IncrementalAverage {
/// Implement the formula for calculating an incremental average.
///
/// https://math.stackexchange.com/questions/106700/incremental-averageing
fn add_value(&mut self, value: f64) {
self.count += 1;
let new_count_float = f64::from(self.count);
let value_average_difference = value - self.average;
let difference_over_count = value_average_difference / new_count_float;
let new_average = self.average + difference_over_count;
self.average = new_average;
}
}
#[smartmodule(aggregate)]
pub fn aggregate(accumulator: RecordData, current: &Record) -> Result<RecordData> {
// Parse the average from JSON
let mut average: IncrementalAverage =
serde_json::from_slice(accumulator.as_ref()).unwrap_or_default();
// Parse the new value as a 64-bit float
let value = std::str::from_utf8(current.value.as_ref())?
.trim()
.parse::<f64>()?;
average.add_value(value);
let output = serde_json::to_vec(&average)?;
Ok(output.into())
}
I quite like this example, because the most complicated thing that’s going on here is just the math for calculating an incremental average. Let’s look at some of the key elements at play:
- We have an
IncrementalAveragetype that holds our running average value along with the number of values that have been added to this average- This is what we use as our
accumulator - This value is serialized to JSON and becomes part of our output stream
- This is what we use as our
IncrementalAverage::add_valueimplements the formula for incremental averaging
Let’s look at the body of the main aggregate function piece-by-piece to help us reason
about the work that’s being done.
// Parse the average from JSON
let mut average: IncrementalAverage =
serde_json::from_slice(accumulator.as_ref()).unwrap_or_default();
Here, we’re asking serde_json to try to deserialize our accumulator as an instance of
IncrementalAverage. Looking at the struct definition, we can see that this should expect
JSON objects that look approximately like this:
{"average":0.0,"count":0}
Incidentally, this specific value is what this code will give us if serde_json::from_slice
fails to parse our JSON from the accumulator input. This is because .unwrap_or_default()
will provide Default::default() if an error occurs during parsing, and the
default value for IncrementalAverage has a zero in each field.
After we parse our accumulator as an IncrementalAverage, the next bit is:
// Parse the new value as a 64-bit float
let value = std::str::from_utf8(current.value.as_ref())?
.trim()
.parse::<f64>()?;
Here, we’re parsing our input record as a string, and then into a 64-bit float, returning an error if either of those steps fails.
The next line is where the actual work gets done, by adding our new value to our running average. I’ve re-pasted the running-average calculation below as well.
average.add_value(value); // this calls the function below
// Explanation at https://math.stackexchange.com/questions/106700/incremental-averageing
fn add_value(&mut self, value: f64) {
self.count += 1;
let new_count_float = f64::from(self.count);
let value_average_difference = value - self.average;
let difference_over_count = value_average_difference / new_count_float;
let new_average = self.average + difference_over_count;
self.average = new_average;
}
Without getting too far into the math, an average is basically the sum-of-inputs over
the number-of-inputs. To add a new input, we can “undo” the division, add our new input
to the sum, and re-divide by the new number of inputs. This is the reason that we have
to keep track of both the average and the count in our IncrementalAverage type.
The last thing left to do is serialize our updated accumulator and return it:
let output = serde_json::to_vec(&average)?;
Ok(output.into())
Let’s take this for a test drive. Create a new topic for our averaging.
$ fluvio topic create aggregate-average
topic "aggregate-average" created
Let’s produce some numbers to average:
$ fluvio produce aggregate-average
> 2
Ok!
> 4
Ok!
> 6
Ok!
> 8
Ok!
> 10
Ok!
> 12
Ok!
> ^C
Make sure to build the new SmartModule, then consume with it.
$ cargo build --release
$ fluvio consume aggregate-average -B --aggregate=target/wasm32-unknown-unknown/release/aggregate_blog_average.wasm
Consuming records from the beginning of topic 'aggregate-average'
{"average":2.0,"count":1}
{"average":3.0,"count":2}
{"average":4.0,"count":3}
{"average":5.0,"count":4}
{"average":6.0,"count":5}
{"average":7.0,"count":6}
I happened to find a sequence of inputs that gives very nice round averages, but you can test this out with any decimal numbers and see that the averages are coming out as expected.
Our last example will showcase both a structured accumulator and structured input records 👇
Example #4: Sum a key-value object point-by-point
For this last example, suppose we had a real-time stream representing new stars on GitHub repositories, and that the events in this stream described which repositories received stars and how many stars were added.
{"infinyon/fluvio":7,"serde-rs/serde":8}
{"infinyon/fluvio":4,"serde-rs/serde":5,"serde-rs/json":7}
{"serde-rs/serde":11,"serde-rs/json":6,"infinyon/node-bindgen":3}
We can create an Aggregate function to sum up these objects point-by-point, so that the numbers on matching keys are added to each other, and unique repositories maintain independent sums. We would expect the aggregate of the above to look like:
{"infinyon/fluvio":7,"serde-rs/serde":8}
{"infinyon/fluvio":11,"serde-rs/serde":13,"serde-rs/json":7}
{"infinyon/fluvio":11,"serde-rs/serde":24,"serde-rs/json":13,"infinyon/node-bindgen":3}
Follow along: create a new project
Let’s create one last aggregate-blog-stars template project:
$ cargo generate --git https://github.com/infinyon/fluvio-smartmodule-template
⚠️ Unable to load config file: ~/.cargo/cargo-generate.toml
🤷 Project Name : aggregate-blog-stars
🔧 Generating template ...
✔ 🤷 Which type of SmartModule would you like? · aggregate
[1/7] Done: .cargo/config.toml
[2/7] Done: .cargo
[3/7] Done: .gitignore
[4/7] Done: Cargo.toml
[5/7] Done: README.md
[6/7] Done: src/lib.rs
[7/7] Done: src
🔧 Moving generated files into: `aggregate-blog-stars`...
✨ Done! New project created aggregate-blog-stars
Let’s jump right into the code for this example.
$ cd aggregate-blog-average
Paste the following code into your src/lib.rs file:
use std::collections::HashMap;
use fluvio_smartmodule::{smartmodule, Result, Record, RecordData};
use serde::{Serialize, Deserialize};
#[derive(Default, Serialize, Deserialize)]
struct GithubStars(HashMap<String, u32>);
impl std::ops::Add for GithubStars {
type Output = Self;
fn add(mut self, next: Self) -> Self::Output {
for (repo, new_stars) in next.0 {
self.0.entry(repo)
.and_modify(|stars| *stars += new_stars)
.or_insert(new_stars);
}
self
}
}
#[smartmodule(aggregate)]
pub fn aggregate(accumulator: RecordData, current: &Record) -> Result<RecordData> {
// Parse accumulator
let accumulated_stars: GithubStars =
serde_json::from_slice(accumulator.as_ref()).unwrap_or_default();
// Parse next record
let new_stars: GithubStars = serde_json::from_slice(current.value.as_ref())?;
// Add stars and serialize
let summed_stars = accumulated_stars + new_stars;
let summed_stars_bytes = serde_json::to_vec_pretty(&summed_stars)?;
Ok(summed_stars_bytes.into())
}
One thing I’d like to point out right off the bat is that the general flow for each of the Aggregate examples we’ve looked at is pretty much the same. In each example, we:
- Parse the accumulator and input record into a structured form
- Add the input record to the accumulator
- Serialize the accumulator and return it
I’ve personally found it very helpful to define a custom type to represent the accumulator, and to define an associated function that describes how to “merge” the structured input record into the structured accumulator. Let’s take a look at how this works in this example.
Here, I’ve created a custom type called GithubStars that is used both as our
structured accumulator and input record. Recall from the previous example that
the accumulator and record do not always need to be the same type, but in this case
it just-so-happened that way.
GithubStars is just a wrapper around HashMap<String, u32>, which allows it to
deserialize from a JSON object with arbitrary strings as keys and positive integers
as values. The interesting part here is the impl std::ops::Add for GithubStars,
which describes how to “add” two of these values together, even allowing us to use
the + operator when we have two values of this type. Let’s take a closer look at
this implementation:
impl std::ops::Add for GithubStars {
type Output = Self;
fn add(mut self, next: Self) -> Self::Output {
for (repo, new_stars) in next.0 {
self.0.entry(repo)
.and_modify(|stars| *stars += new_stars)
.or_insert(new_stars);
}
self
}
}
Here, both self and next are instances of GithubStars. In this case, self
will be our accumulator value and next will be the structured input record. We
essentially want to add all the entries from next to the corresponding entries
of self. Since HashMap<String, u32> implements IntoIterator, we can iterate
over the key/value pairs in a plain-old for loop.
Inside the loop, we’re making use of the incredible Entry API for Rust HashMaps which allows us to insert and manipulate elements in-place with a buttery-smooth call chain. The three lines here describe what’s happening almost in plain English:
- Find the entry in the map for a key called
repo - If this entry exists, modify the value there by adding
new_starsto it - If this entry didn’t exist, initialize it by inserting
new_starsas the value there
This is one of my favorite APIs in the Rust standard library, if you haven’t seen it before I highly recommend going to read about it!
Anyways, let’s try this out and see if everything works as expected! Let’s create a new topic and produce some data:
$ fluvio topic create aggregate-stars
topic "aggregate-stars" created
$ fluvio produce aggregate-stars
> {"infinyon/fluvio":7,"serde-rs/serde":8}
Ok!
> {"infinyon/fluvio":4,"serde-rs/serde":5,"serde-rs/json":7}
Ok!
> {"serde-rs/serde":11,"serde-rs/json":6,"infinyon/node-bindgen":3}
Ok!
Let’s make sure to compile our SmartModule, then we can open up a consumer on our Topic.
$ cargo build --release
$ fluvio consume aggregate-stars -B --aggregate=target/wasm32-unknown-unknown/release/aggregate_blog_average.wasm
Consuming records from the beginning of topic 'aggregate-stars'
{
"infinyon/fluvio": 7,
"serde-rs/serde": 8
}
{
"infinyon/fluvio": 11,
"serde-rs/serde": 13,
"serde-rs/json": 7
}
{
"infinyon/node-bindgen": 3,
"infinyon/fluvio": 11,
"serde-rs/serde": 24,
"serde-rs/json": 13
}
Tada, we got the same numbers we were expecting! Note that we’re getting an expanded
“pretty” print of the accumulator output, this is because we used
serde_json::to_vec_pretty when we serialized our output.
Conclusion
I had quite a lot of fun writing this post, I think that Aggregates are going to be one of the most interesting SmartModules in terms of potential use-cases that can be solved with them. I’m excited to hear feedback and ideas for how this could be applied, be sure to join the discussion on Reddit and come talk to us on Discord, we’re happy to talk and answer any questions. Until next time!
Update: SmartModules were originally called SmartStreams. The blog was updated to reflect the new naming convention