Use Cases
Docs
Blog Articles
BlogResources
Pricing
PricingUsing DuckDB with Fluvio

Co-founder & CTO, InfinyOn

DuckDB is an open-source SQL OLAP database that’s lightweight, fast, and user-friendly, a perfect match for Fluvio data streaming. Integrating these two technologies is a step toward Real-Time OLAP. This blog will show how to use Fluvio SmartModules and DuckDb SQL to transform data records and generate powerful materialized views.
Prerequisite
This blog assumes that you have already installed Fluvio and have a running cluster. You have 2 options:
- Sign-up for InfinyOn Cloud
- You’ll need an InfinyOn Cloud account to download
joltfrom SmartModule Hub
- You’ll need an InfinyOn Cloud account to download
- Install Fluvio on your local machine
Let’s get started.
Data Source
In this example, we will consume live data from transit vehicles in Helsinki, Finland. The city publishes real-time metrics such as speed, acceleration, route, etc., and makes this data publicly available via MQTT. We will read this data and calculate the average speed per vehicle.
Use Fluvio CDK to setup up an MQTT Connector
We will use Fluvio’s Connector Developer Kit (CDK) to setup MQTT connector.
Building CDK
This section assumes that you have Rust installed. Please follow setup instructions to install Rust and Cargo.
Clone the Fluvio repository:
$ git clone https://github.com/infinyon/fluvio.git
Build CDK:
$ cd fluvio; make build-cdk RELEASE=true
Check that the binary has been generated
$ ls target/release/cdk
target/release/cdk
For convenience, you may want to copy the binary to your PATH.
Building MQTT Connector using CDK
Now, we can deploy the MQTT connector using CDK. First, we clone the new MQTT connector repository.
Clone MQTT connector repository:
$ cd ..; git clone https://github.com/infinyon/mqtt-connector.git
Use CDk to build mqtt-connector:
$ cd mqtt-connector; ../fluvio/target/release/cdk build
Deploying MQTT Connector to connect to Helsinki MQTT Broker
Create following configuration file h1.yaml:
meta:
version: latest
name: h2
type: mqtt-source
topic: veh1
create-topic: true
mqtt:
url: "mqtt://mqtt.hsl.fi"
topic: "/hfp/v2/journey/ongoing/vp/+/+/+/#"
client_id: "fluvio-mqtt"
timeout:
secs: 30
nanos: 0
payload_output_type: json
Then run following command to start MQTT connector:
$ ../fluvio/target/release/cdk deploy start --config h1.yaml
This will start MQTT connector and connect to Helsinki MQTT broker. It will subscribe to the topic /hfp/v2/journey/ongoing/vp/+/+/+/# and publish the data to Fluvio topic veh1.
You can verify that the connector is running by running following command:
$ fluvio consume veh1
Consuming records from 'veh1'
{"mqtt_topic":"/hfp/v2/journey/ongoing/vp/bus/0012/02244/1098/1/Rastila(M)/19:03/1453126/5/60;25/20/07/96","payload":{"VP":{"desi":"98","dir":"1","oper":12,"veh":2244,"tst":"2023-02-02T17:00:15.231Z","tsi":1675357215,"spd":0.0,"hdg":244,"lat":60.209415,"long":25.076423,"acc":0.0,"dl":179,"odo":90,"drst":0,"oday":"2023-02-02","jrn":304,"line":145,"start":"19:03","loc":"GPS","stop":1453126,"route":"1098","occu":0}}}
.....
If you are using InfinyOn Cloud, checkout the Dashboard:
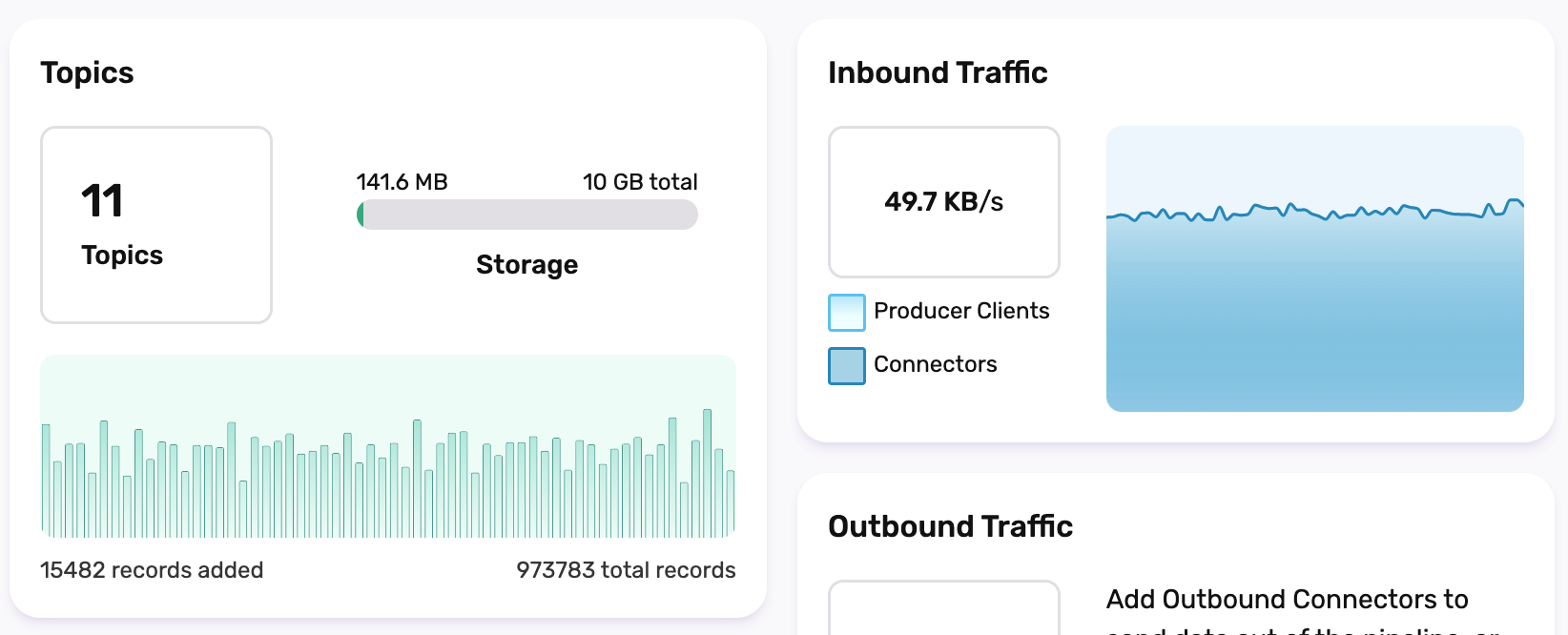
This is lots of data.
Building DuckDB Fluvio extension
Fluvio-duck is a Fluvio extension that allows DuckDB to query data from Fluvio. It’s still in development and not yet published to crates.io. So we will need to build it from source.
Pre-requisite
Building Fluvio-Duck requires full build of DuckDB which requires CMake.
Install on Mac:
$ brew install cmake
For other platforms, please follow CMake installation instructions here.
Downloading and building Fluvio-Duck
Clone the repository:
$ cd .. && git clone --recurse-submodules https://github.com/infinyon/fluvio-duck.git
As a workaround please add the following to CMakeLists.txt:
target_link_libraries(${LIB_NAME}
"${CMAKE_BINARY_DIR}/src/libduckdb_static.a")
Then build the extension:
$ cd fluvio-duck && make release
This will take a while… good time for a coffee break.
Once it is done, both DuckDB and Fluvio-Duck will be stored in the .build/release directory.
Querying data from Fluvio using DuckDB
Now we are ready to query data from Fluvio using DuckDB. The Fluvio-Duckdb extension is using development version of DuckDB. So we will need to start DuckDB build from prev steps.
Run DuckDb:
$ ./build/release/duckdb --unsigned
Loading extension:
D load './build/release/extension/fluvio-duck/fluvioduck.duckdb_extension';
Now we can use the extension to query data from Fluvio.
Getting topics and partitions
Fluvio object such as topics and partitions can be queried directly from DuckDB.
Retrieve topics:
D select * from fluvio_topics();
┌─────────┬────────────┐
│ name │ partitions │
│ varchar │ int32 │
├─────────┼────────────┤
│ veh1 │ 1 │
└─────────┴────────────┘
Topic h1 was created by the MQTT connector. If there are other topics they are also displayed.
D select * from fluvio_partitions();
┌─────────┬───────────┬───────┐
│ topic │ partition │ LEO │
│ varchar │ varchar │ int32 │
├─────────┼───────────┼───────┤
│ veh1 │ 0 │ 28994 │
└─────────┴───────────┴───────┘
Querying Fluvio topics
With SQL, you can query Fluvio topics and materialize as SQL table.
The SQL command has the following format:
D select <param> from fluvio_consume('<topic_name> <options>');
Feed Fluvio CLI commands as function parameters and queries as SQL parameters.
For example, run the following command to get last 5 events from topic h1:
D select * from fluvio_consume('veh1 --tail 5');
┌────────┬──────────────────────┬─────────────────────────────────────────────────────────────────────────────────────┐
│ offset │ timestamp │ value │
│ int32 │ timestamp_ms │ varchar │
├────────┼──────────────────────┼─────────────────────────────────────────────────────────────────────────────────────┤
│ 100914 │ 2023-02-02 17:10:5… │ {"mqtt_topic":"/hfp/v2/journey/ongoing/vp/bus/0022/00921/2549/2/Tapiola (M)/18:44… │
│ 100915 │ 2023-02-02 17:10:5… │ {"mqtt_topic":"/hfp/v2/journey/ongoing/vp/bus/0022/00967/2582/2/Espoon keskus/18:… │
│ 100916 │ 2023-02-02 17:10:5… │ {"mqtt_topic":"/hfp/v2/journey/ongoing/vp/bus/0022/01143/2510/2/Herttoniemi(M)/18… │
│ 100917 │ 2023-02-02 17:10:5… │ {"mqtt_topic":"/hfp/v2/journey/ongoing/vp/train/0090/06055/3001R/1/Riihimäki/16:3… │
│ 100918 │ 2023-02-02 17:10:5… │ {"mqtt_topic":"/hfp/v2/journey/ongoing/vp/train/0090/01081/3001I/1/Lentoas. - Hel… │
└────────┴──────────────────────┴─────────────────────────────────────────────────────────────────────────────────────┘
You can ask for Fluvio help by using the --help option:
D select * from fluvio_consume('--help');
.... help command output
Using SmartModules to transform MQTT data
Fluvio connector converts the MQTT data to JSON format. Next, we can use Fluvio SmartModules to transform the data and make it suitable for queries and analytics.
In this case, we only want the following fields from the data lat, long, veh. While at it, we also want to rename fields for readability: veh to vehicle. The jolt SmartModule published in the SmartModule Hub can be used for this purpose.
To download the jolt SmartModule, you’ll need an InfinyOn Cloud account.
Download the SmartModule using fluvio CLI:
$ fluvio hub sm download infinyon/[email protected]
downloading infinyon/[email protected] to infinyon-jolt-0.3.0.ipkg
... downloading complete
... checking package
trying connection to fluvio router.infinyon.cloud:9003
... cluster smartmodule install complete
Transformation file
The Jolt transformation step is defined in the following YAML file: jolt.yaml
transforms:
- uses: infinyon/[email protected]
with:
spec:
- operation: shift
spec:
payload:
VP:
lat: "lat"
long: "long"
veh: "vehicle"
route: "route"
spd: "speed"
tst: "tst"
Querying with transformation
To get last 10 events from topic veh1 and transform the data using jolt.yaml file:
D select * from fluvio_consume('veh1 --tail 5 --transforms-file=jolt.yaml');
┌────────┬──────────────────────┬─────────────────────────────────────────────────────────────────────────────────────┐
│ offset │ timestamp │ value │
│ int32 │ timestamp_ms │ varchar │
├────────┼──────────────────────┼─────────────────────────────────────────────────────────────────────────────────────┤
│ 728564 │ 1969-12-31 23:59:5… │ {"lat":60.172147,"long":24.947603,"route":"1055","speed":5.96,"tst":"2023-02-02T1… │
│ 728565 │ 1969-12-31 23:59:5… │ {"lat":60.20546,"long":24.878425,"route":"1500","speed":4.99,"tst":"2023-02-02T17… │
│ 728566 │ 1969-12-31 23:59:5… │ {"lat":60.178948,"long":24.828018,"route":"2550","speed":9.72,"tst":"2023-02-02T1… │
│ 728567 │ 1969-12-31 23:59:5… │ {"lat":60.209576,"long":25.076889,"route":"1082","speed":0.0,"tst":"2023-02-02T17… │
....
Mapping JSON columns to SQL columns
In the previous example, the JSON data is returned as a single column. That still make harder to analyze using SQL or DuckDB. You can map the JSON columns to SQL columns using the -c option. The -c option takes a column name and a JSON path. The JSON path is a dot separated path to the JSON column. For example, to map the lat column to d column, you can use -c lat:d="lat".
Following example show how to create materialized view with mapped columns:
D create view transit as select * from fluvio_consume('
veh1
--tail 5
--transforms-file=jolt.yaml
-c lat:d="lat"
-c long:d="long"
-c vehicle:i="vehicle"
-c route="route"
-c speed:d="speed"
-c time:t="tst"
');
Let’s run it:
D select * from transit;
┌─────────────┬─────────────┬─────────┬─────────┬────────┬─────────────────────────┐
│ lat │ long │ vehicle │ route │ speed │ time │
│ double │ double │ int32 │ varchar │ double │ timestamp_ms │
├─────────────┼─────────────┼─────────┼─────────┼────────┼─────────────────────────┤
│ 60.208204 │ 24.974945 │ 693 │ 1055 │ 0.01 │ 2023-02-02 17:27:34.587 │
│ 60.208783 │ 24.947053 │ 19 │ 1069 │ 3.66 │ 2023-02-02 17:27:34.564 │
│ 60.741549 │ 24.782922 │ 6079 │ 3001R │ 0.0 │ 2023-02-02 17:27:34.558 │
│ 60.178087 │ 24.950206 │ 424 │ 1006 │ 2.83 │ 2023-02-02 17:27:34.57 │
│ 60.221636 │ 24.896216 │ 1416 │ 1052 │ 11.21 │ 2023-02-02 17:27:34.553 │
├─────────────┴─────────────┴─────────┴─────────┴────────┴─────────────────────────┤
│ 5 rows 6 columns │
└──────────────────────────────────────────────────────────────────────────────────┘
Now fields are mapped into SQL readable columns, you can use SQL commands to perform analysis on the data. For example, let’s get the average speed of the vehicles by route:
D select route, avg(speed) from transit group by route;
┌─────────┬──────────────────────┐
│ route │ avg(speed) │
│ varchar │ double │
├─────────┼──────────────────────┤
│ 31M2 │ 17.02 │
│ 31M1 │ 12.065000000000001 │
│ 9641 │ 12.66 │
│ 1071 │ 7.045 │
│ 1506 │ 4.605 │
├─────────┴──────────────────────┤
│ 5 rows 2 columns │
└────────────────────────────────┘
Converting fluvio topic data to Parquet
Previous examples show how to consume data from fluvio topics and perform SQL analysis on the data. You can also convert the data to Parquet format and perform analysis using Parquet tools. To convert the data to Parquet format, you can use the COPY command:
First install Parquet extensions into DuckDB:
D INSTALL parquet; Load 'parquet';
The comman structure to copy data into a parquet format is the following:
D COPY (SELECT * FROM <fluvio_topic>) TO '<parquet_file>' (FORMAT 'parquet');
To convert the data from transit materialized view to helsinki.parquet file, you can run the following command:
D COPY (SELECT * FROM transit) TO 'helsinki.parquet' (FORMAT 'parquet');
To read back from the parquet file, use:
D select * from read_parquet('helsinki.parquet') ;
┌─────────────┬─────────────┬─────────┬─────────┬────────┬─────────────────────────┐
│ lat │ long │ vehicle │ route │ speed │ time │
│ double │ double │ int32 │ varchar │ double │ timestamp_ms │
├─────────────┼─────────────┼─────────┼─────────┼────────┼─────────────────────────┤
│ 60.208204 │ 24.974945 │ 693 │ 1055 │ 0.01 │ 2023-02-02 17:27:34.587 │
│ 60.208783 │ 24.947053 │ 19 │ 1069 │ 3.66 │ 2023-02-02 17:27:34.564 │
│ 60.741549 │ 24.782922 │ 6079 │ 3001R │ 0.0 │ 2023-02-02 17:27:34.558 │
│ 60.178087 │ 24.950206 │ 424 │ 1006 │ 2.83 │ 2023-02-02 17:27:34.57 │
│ 60.221636 │ 24.896216 │ 1416 │ 1052 │ 11.21 │ 2023-02-02 17:27:34.553 │
├─────────────┴─────────────┴─────────┴─────────┴────────┴─────────────────────────┤
│ 5 rows 6 columns │
└──────────────────────────────────────────────────────────────────────────────────┘
Conclusion
In this blog post, we showed that it is possible to use DuckDB to perform SQL analysis on data from Fluvio topics. This is just beginning of the integration between Fluvio and DuckDB. Join our community on Discord to give us feedback on the integration of Fluvio and DuckDB. Let us know if there are other use cases you’ll find valuable.