Use Cases
Docs
Blog Articles
BlogResources
Pricing
PricingHow to build an autonomous news Generator with AI using Fluvio


Contributor, InfinyOn

Vincent Lee published this article originally on Substack as a two part series on building an event-driven architecture with Fluvio. This is the second part of the tutorial.
How to build an autonomous news Generator with AI using Fluvio
Introduction
In the previous article, I introduced the concept of event-driven architecture (EDA) and demonstrated its capabilities using Fluvio. I showcased how an application could leverage EDA to asynchronously send quotes from a publisher to subscribers at regular intervals.
In this article, I will expand upon my previous work by introducing additional features that enhance the application’s functionality. I will delve into how to integrate a search engine to discover relevant quotes and utilize Large Language Models (LLMs) to summarize these quotes effectively. By combining these elements, I aim to create a more robust and informative application that leverages the power of EDA and AI, named Wipe.
What is Wipe?
Tired of Falling Behind in the Fast-Paced World of AI? I understand the frustration of trying to keep up with the constant stream of new technologies and trends in the AI landscape. It can be overwhelming to stay informed about the latest developments while also focusing on building your projects.
Introducing Wipe, your AI-powered solution. By leveraging a powerful combination of search engines and Large Language Models, Wipe automatically curates the most relevant AI news and condenses it into concise summaries. No more sifting through countless articles. With Wipe, you can stay ahead of the curve and ensure your projects are always built with the latest insights and technologies.
Features
As an AI enthusiast, I’ve often found myself asking: How can I stay up-to-date with the rapid advancements in this field? Is there a way to capture the essence of countless articles in a matter of seconds?

Wipe, your AI-powered solution, offers the following benefits:
- Real-time Updates: Stay informed about the latest AI trends and breakthroughs.
- Instant Summarization: Use Large Language Models to quickly grasp the key points of articles.
Workflow
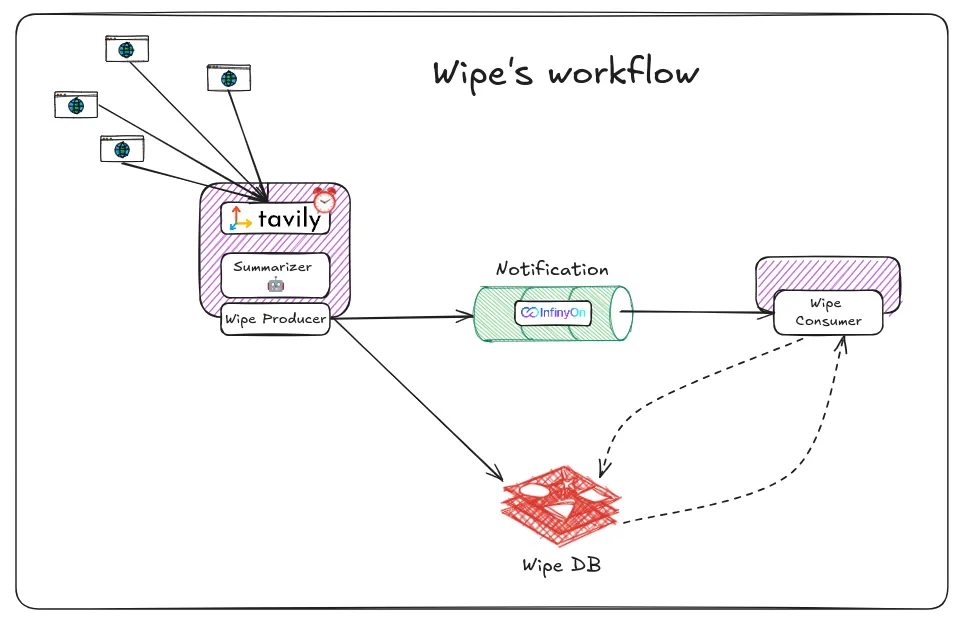
- Data Ingestion: The Publisher continuously collects and ingests raw AI trend data from various sources.
- Feature Extraction: The Feature component processes this data, extracting relevant features and insights through techniques like natural language processing and data analysis.
- Content Refinement: The Feature component further refines the extracted content, summarizing key points or providing additional context.
- Notification Distribution: The Notification component sends the processed and refined AI trend updates to interested Consumers. In these settings, fluvio handles this component very pretty.
- Consumer Utilization: Consumers receive these updates and leverage them for their specific AI applications, such as model training, product development, or research.
Prerequisites
Event-driven Architecture (EDA)
I would love to remind myself a little bit about the EDA. Event-driven architecture is a design pattern where applications respond to events asynchronously. This allows for greater scalability and responsiveness compared to traditional request-response models. Events can be triggered by various sources, such as user actions, system changes, or external data feeds.
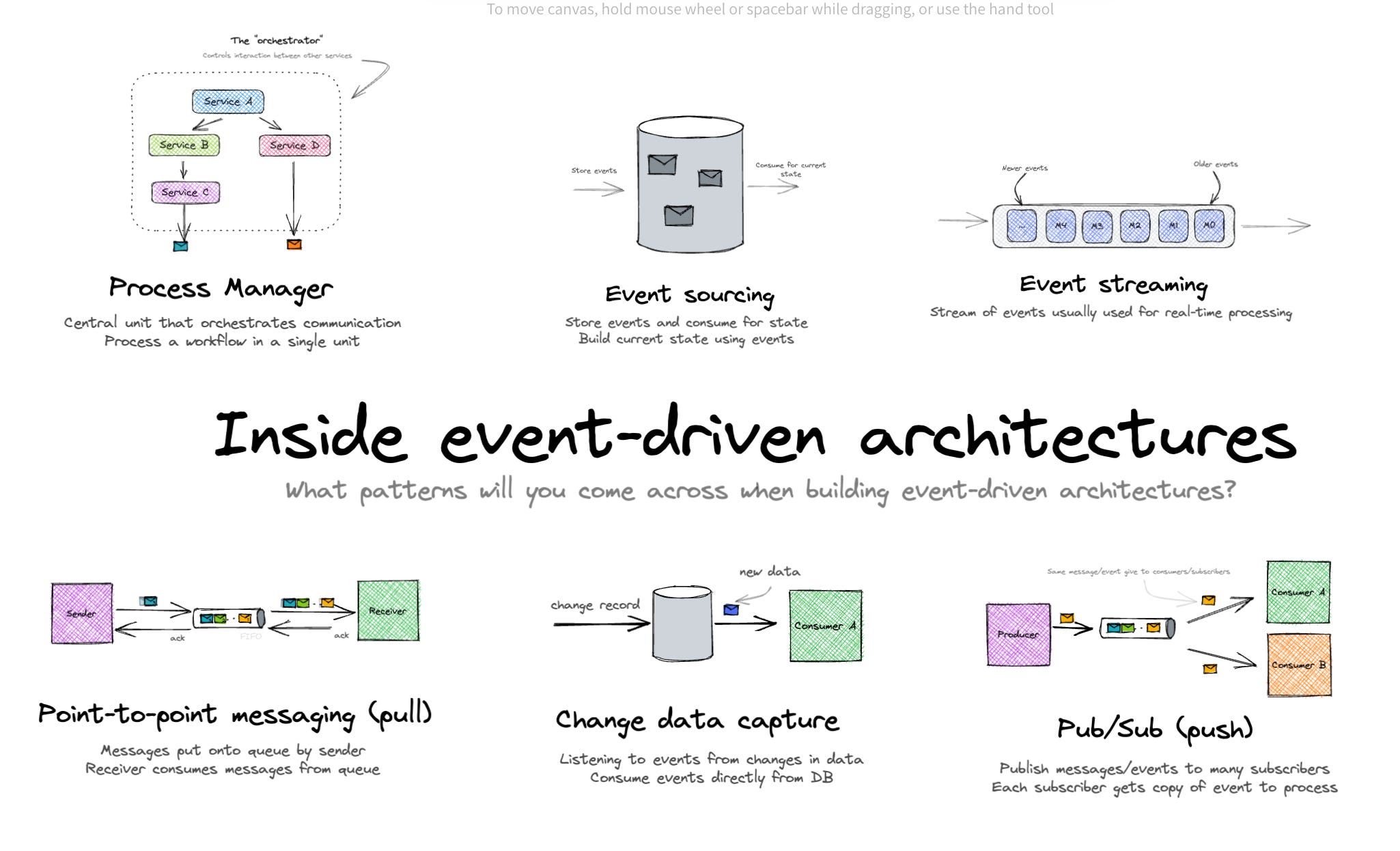
EDA is widely used in various domains, including:
- Real-time data processing: Processing financial market data, IoT sensor data, and other time-sensitive information.
- Microservices architecture: Decoupling services, facilitating asynchronous communication, and enabling independent scaling.
- Serverless computing: Executing functions in response to events, such as file uploads, database changes, or API calls.
Tech-Stack
At the core of Wipe lies a robust technological stack designed to deliver real-time updates and insightful summaries. Let’s break down the key components:
- Fluvio: As a high-performance streaming engine, Fluvio efficiently handles the continuous flow of data, ensuring that news articles are processed and delivered promptly. Its Rust-based architecture guarantees low latency and security.
- Redis: This in-memory data store acts as a central hub, storing and retrieving data seamlessly between the publisher and consumer components.
- Langchain: By providing a vast array of Large Language Models (LLMs), Langchain empowers Wipe to understand and summarize complex articles with exceptional accuracy.
- Tavily Search: This AI-integrated search engine plays a crucial role in identifying relevant news articles, ensuring that Wipe delivers only the most pertinent information to its users.
Together, these components form a powerful synergy that enables Wipe to provide users with timely, accurate, and informative AI news updates.
Getting Started
Wipe relies heavily on Docker; therefore, you should utilize Docker to get the best result. First and foremost, let’s clone the repository:
git clone <https://github.com/MinLee0210/Wipe.git>
cd ./Wipe
pip install -r requirements.txt
Environment Setup
To setup the environment for the project, you must to:
- Install the Fluvio (view previous article or on Fluvio website).
- Install Redis (Wipe used Redis on Docker, I’ll leave the link here).
- Get API keys from Tavily (a must) and a LLM’s provider that you want to use (Gemini, Groq, OpenAI), remember to change the configuration from
config.yamlfile.
Make sure to create a .env file that follows this structure:
TAVILY_API_KEY=""
GEMINI_API_KEY=""
GROQ_API_KEY=""
Experiment Setup
I can not show everything of the code in this blog; however, I will show 3 most important components of the app and the logic of the news_features .
- The WipeProducer.
- The WipeConsumer.
- The WipeDB.
Before deep dive into those 3 components, I will show the get_latest_trends()function that allows getting the latest trends in the AI field.
TREND = "What is the latest trend in AI 2024?"
def get_latest_trend() -> tuple[list[Article], list[Event]]:
"""
Retrieves the latest trend in AI and returns a list of summarized articles.
Returns:
list[Article]: A list of Article objects containing summaries of relevant news.
"""
# Find relevant URLs
urls = [result["url"] for result in searcher.run(TREND)["results"]]
# Filter out unsupported URLs and scrape content
docs = []
for url in urls:
try:
docs.append(scraper.run(url))
except ValueError:
continue # Skip unsupported URLs
# Process and summarize articles
articles, events = [], []
for idx, doc in enumerate(docs):
metadata = doc[0].metadata
content = clean(doc[0].page_content)
summary_prompt = SUMMARY_ARTICLE.format(article=content)
summary = llm.invoke(summary_prompt).content
# Create Article object with metadata and summary
article = Article(summary=summary, **metadata)
articles.append(article)
# Create Event object with Article's information
event_title = f"Latest Trend in AI (2024) - {article.title}" # Modify title creation if needed
event = Event(title=event_title,
article_id=article.id)
events.append(event)
return (articles, events)
The TREND is defined to be strict and related to our topic ai-trends. However, it can be extended further into any topics that you want it to be. The flow of the algorithm behaves as follows:
- It gets trends from a bunch of websites that are relevant based on Tavily Search Engine.
- Those websites are then scrapped via LangChain’s WebBaseLoader and summarized via an LLM (I used Gemini; additionally, you can use another library to simplify this stage, such as ScrapeGraphAI).
- The processed documents are then fed into 2 objects: Event and Article. The former is sent to the Consumer to notify them there are new trends that are gathered successfully; the latter is saved in the database, and based on the Consumer’s choice, the Article is then read by getting it from the database.
WipeProducer
Here is the code of the Producer:
"""
A simple Fluvio producer that produces records to a topic.
"""
import subprocess
from fluvio import Fluvio
class WipeProducer:
"""
A class to produce records to a Fluvio topic.
Attributes:
----------
topic_name : str
The name of the topic to produce to.
partition : int
The partition to produce to.
producer : Fluvio.topic_producer
The Fluvio producer object.
Methods:
-------
produce_records(num_records)
Produces a specified number of records to the topic.
flush()
Flushes the producer to ensure all records are sent.
"""
ROLE = "producer"
def __init__(self, topic_name: str, partition: int):
"""
Initializes the FluvioProducer object.
Parameters:
----------
topic_name : str
The name of the topic to produce to.
partition : int
The partition to produce to.
"""
self.topic_name = topic_name
self.partition = partition
self.producer = Fluvio.connect().topic_producer(topic_name)
def produce_records(self, event: str) -> None:
"""
Produces a specified event.
Parameters:
----------
event : str
The information of the event
"""
try:
self.producer.send_string(event)
except Exception as e:
print(f"Error producing records: {e}")
def flush(self) -> None:
"""
Flushes the producer to ensure all records are sent.
"""
try:
self.producer.flush()
print("Producer flushed successfully")
except Exception as e:
print(f"Error flushing producer: {e}")
def __create_topic(self, topic_name:str):
"""
Create a topic.
Parameters:
----------
topic_name: str
The name of the topic
"""
try:
shell_cmd = ['fluvio', 'topic', 'create', topic_name]
subprocess.run(shell_cmd, check=True)
except subprocess.CalledProcessError as e:
print(f'Command {e.cmd} failed with error {e.returncode}')
The Producer object has 3 main methods:
- Connect to the chosen topic via the constructor.
- Send records to the Consumer.
- Flushes the producer to ensure all records are sent.
I also provide a method for Python code to execute shell commands, allowing creating topics via the Producer interface.
The logic of the Producer is defined as:
producer = WipeProducer(topic_name=config["pubsub"]["topic"],
partition=config["pubsub"]["partition"])
# ===== PRODUCER'S METHODS =====
def pub_produce_articles():
"""
Publishes summarized articles to the defined topic.
"""
trends = get_latest_trend() # (articles, events)
for article, event in zip(trends[0], trends[1]):
event_str = json_to_str(event.json())
producer.produce_records(event_str) # Serialize event to JSON
article_str = json_to_str(article.json())
wipe_db.set_article(id=article.id,
role=producer.ROLE,
content=article_str)
producer.flush()
WipeConsumer
The implementation of the WipeConsumer is as follows:
"""
A simple Fluvio consumer that consumes records from a topic.
"""
from datetime import datetime
from fluvio import Fluvio, Offset
class WIPEConsumer:
"""
A class to consume records from a Fluvio topic.
Attributes:
----------
role : str
The role of the consumer (in this case, 'customer').
topic_name : str
The name of the topic to consume from.
partition : int
The partition to consume from.
consumer : Fluvio.partition_consumer
The Fluvio consumer object.
Methods:
-------
consume_records(num_records)
Consumes a specified number of records from the topic.
"""
ROLE = 'customer'
def __init__(self, topic_name: str, partition: int):
"""
Initializes the WIPEConsumer object.
Parameters:
----------
topic_name : str
The name of the topic to consume from.
partition : int
The partition to consume from.
"""
self.topic_name = topic_name
self.partition = partition
self.consumer = Fluvio.connect().partition_consumer(topic_name, partition)
self.notification = []
def consume_records(self, num_records: int) -> None:
"""
Consumes a specified number of records from the topic.
Parameters:
----------
num_records : int
The number of records to consume.
"""
try:
for idx, record in enumerate(self.consumer.stream(Offset.from_end(num_records))):
print(f"Record {idx+1}: {record.value_string()}: timestamp: {datetime.now()}")
self.notification.append(record.value_string())
if idx >= num_records - 1:
break
except Exception as e:
print(f"Error consuming records: {e}")
def flush(self):
"""
Delete the notification
"""
self.notification = []
The Consumer object has 3 main methods:
- Create a connection to the Producer based on the chosen topic via the constructor.
- Consume the records: Wipe sets the Consumer to consume the 1-latest article from the Producer.
- Delete notification: Everytime the Producer creates an article, it will notify its consumers. The Consumer will then store it in the self.notification; based on the Consumer’s choice, the article is then read by getting it from the database.
The logic of the Consumer is:
# ===== CONSUMER'S METHODS =====
def sub_catch_articles():
"""
Consumes events from the topic and processes them (implementation pending).
"""
logger.info("[CONSUMER]: Catch events from Producer")
consumer.consume_records(config["pubsub"]["num_records_consume"])
def sub_read_articles():
"""
Retrieve articles from the database based on the events.
Note:
Assume the Consumer chose the 1-latest event.
"""
logger.info("[CONSUMER]: Get event")
event = consumer.notification[-1]
while not isinstance(event, dict):
event = str_to_json(event)
logger.info("[CONSUMER]: Get article")
article_id = event['article_id']
article = wipe_db.get_article(id=article_id,
role=consumer.ROLE)
logger.info(f"[CONSUMER]: Reading\n{article}")
WipeDB
For the sake of simplicity, the implementation of the database is quite simple: get and set articles.
"""
Define database logic for WIPE.
"""
import redis
AUTHORIZED_METHODS = {
'get': ['customer', 'producer'],
'set': 'producer'
}
class WIPEDB(object):
"""
A class to handle database operations for WIPE.
Attributes:
----------
server : redis.Redis
The Redis database connection.
Methods:
-------
get_article(id, role)
Retrieves an article from the database.
set_article(id, role)
Sets an article in the database.
"""
def __init__(self, db_config: dict):
"""
Initializes the WIPEDB object.
Parameters:
----------
db_config : dict
A dictionary containing the Redis database configuration.
"""
self.server = self.__set_db_connection(db_config)
def get_article(self, id: str, role: str) -> str:
"""
Retrieves an article from the database.
Parameters:
----------
id : str
The ID of the article to retrieve.
role : str
The role of the user requesting the article.
Returns:
-------
str
The article content if the user is authorized, otherwise None.
"""
if role not in AUTHORIZED_METHODS['get']:
return None
try:
return self.server.get(id)
except redis.exceptions.RedisError as e:
raise e
def set_article(self, id: str, role: str, content: str) -> bool:
"""
Sets an article in the database.
Parameters:
----------
id : str
The ID of the article to set.
role : str
The role of the user setting the article.
content : str
The content of the article.
Returns:
-------
bool
True if the article was set successfully, otherwise False.
"""
if role != AUTHORIZED_METHODS['set']:
return False
try:
self.server.set(id, content)
return True
except redis.exceptions.RedisError as e:
raise e
def __set_db_connection(self, db_config: dict) -> redis.Redis:
"""
Establishes a connection to the Redis database.
Parameters:
----------
db_config : dict
A dictionary containing the Redis database configuration.
Returns:
-------
redis.Redis
The Redis database connection.
"""
try:
server = redis.Redis(**db_config)
return server
except redis.ConnectionError as r_ce:
raise r_ce
To make the app more fun, Wipe constructs the app to have the authorization for interacting with the database. For instance, the Consumer is restricted to make a set method to the database.
Code in Action
From the producer, the code be like:
./producer.py
import time
from controller.pubsub import pub_produce_articles
while True:
pub_produce_articles() # Avg of 35 secs per call.
time.sleep(10)
For every 10 seconds, the Producer will look up the Internet for the latest AI trends.
The Consumer will also get the notification after every 10 seconds:
./consumer.py
import time
import random
from controller.pubsub import sub_catch_articles, sub_read_articles
while True:
sub_catch_articles()
time.sleep(10)
rand_idx = random.randint(a=0, b=10)
if rand_idx % 2 == 0:
sub_read_articles()
For a more engaging experience, I incorporated a random element into the notification system. If the random outcome met specific conditions, the Consumer would be shown the article.
To run the app, simply type
python producer.py &
python cosumer.py
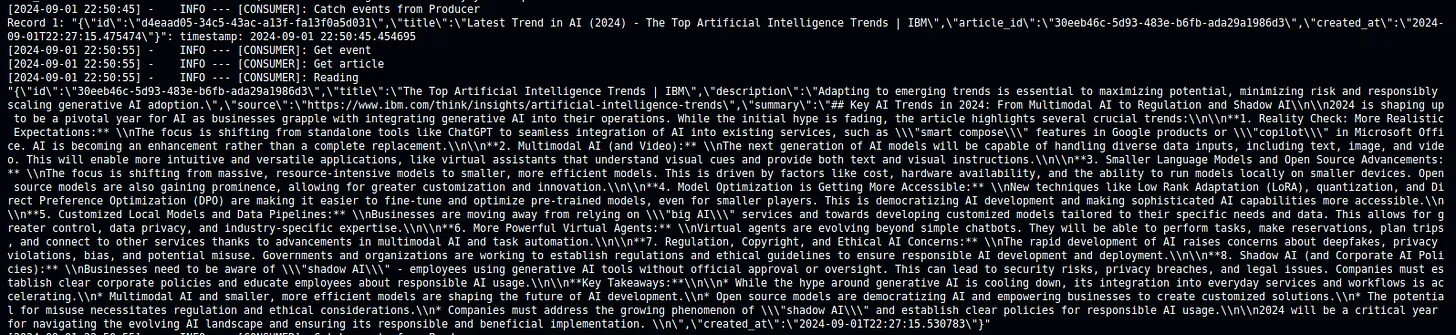
Result
The Producer automatically gets the latest trends from the Internet and uses AI to summarize the website every 10 seconds. After the summarization is done, it makes an event to notify its customers.

The Customer retrieves a notification from its producer. In this experiment, I set it to randomly choose whether to “read” the news from the notification or not.
Conclusion
In this article, I have successfully extended the capabilities of the event-driven architecture (EDA) application introduced in the previous installment.
By integrating a search engine and utilizing Large Language Models (LLMs), the application, now named Wipe, has become a more comprehensive and informative tool. The ability to discover relevant quotes and generate concise summaries enhances the user experience and provides valuable insights into the vast world of AI.
The successful implementation of these features demonstrates the versatility and power of EDA in creating robust and scalable applications.
👉 More details of the code refer to: Github Repository
👉 Follow Vincent: Linkedin | Github
To learn more about how InfinyOn can help you implement event-driven architecture in your data streaming applications, contact us for a demo today.